今天上午群里的一个群友说想爬一个网站的数据,我看了一下觉得挺有意思的嘿,那我用java来搞搞看看

导入Jar包
需要用到Jsoup这个包导入即可
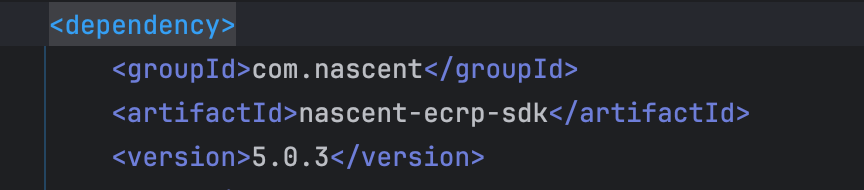
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>分析网页
先浏览器进去群友发的网址,F12看看,找找规律
https://m.jieseba.org/a/jzbj_1.html

发现这地址在 <ul class=”b_boxjw1″> <li> 的 a标签里,这个时候通过标签选择器定位到这个a标签
String html = "https://m.jieseba.org/a/jzbj_1.html";
Document document = Jsoup.connect(html).get();
Elements elements = document.select("div.g_box1 > ul > li > a");//此处是所有a标签的集合然后 再遍历elements获取到这个a标签的href属性 通过拼接地址 得到想要的每个页面的完整链接
https://m.jieseba.org//a/4149.html
for (Element element:elements){
String d_url = element.attr("href");
System.out.println("详情页链接:https://m.jieseba.org/"+d_url);//这个就是网页内容的链接地址
}这个时候看一下详情页的内容,想要的数据都在类为txt1的div下的p标签里,再想上面一样,定位到这个p标签

Document doc = Jsoup.connect("https://m.jieseba.org/"+d_url).get();
Elements select = doc.select("div.g_con > div.txt1 > p");//定位到P标签 此时是P标签集合
定位到P标签之后还是跟上面的步骤一样,循环输出就可以了
for (Element ele : select) {
String index = ele.ownText();
System.out.println(index);
}结果:

完整代码
package cn.3zi.www;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class GrabUrl {
/**测试*/
public static void main(String[] args) throws Exception {
String html = "https://m.jieseba.org/a/jzbj_1.html";
Document document = Jsoup.connect(html).get();
Elements elements = document.select("div.g_box1 > ul > li > a");
for (Element element:elements){
String d_url = element.attr("href");
System.out.println("详情页链接:https://m.jieseba.org/"+d_url);
Document doc = Jsoup.connect("https://m.jieseba.org/"+d_url).get();
Elements select = doc.select("div.g_con > div.txt1 > p");
for (Element ele : select) {
String index = ele.ownText();
System.out.println(index);
}
}
}
}效果展示
原网页:

爬取结果: