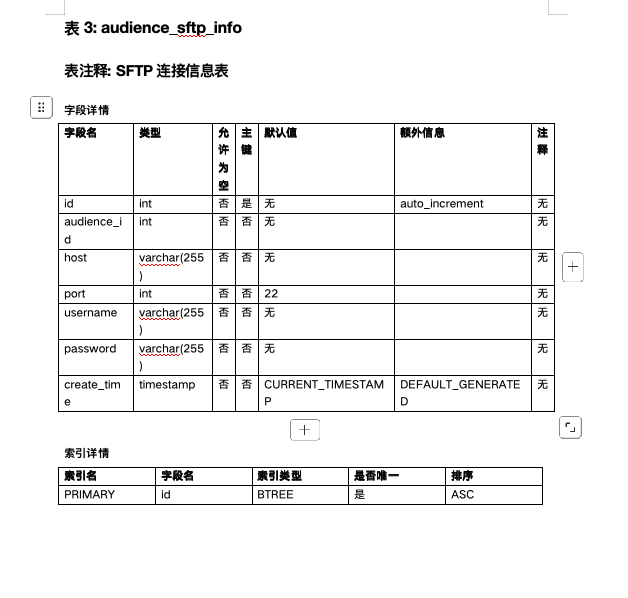
安装依赖
pip3 install mysql-connector-python python-docx脚本代码
import mysql.connector
from mysql.connector import Error
import argparse
from datetime import datetime
from docx import Document
from docx.shared import Inches, Pt
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.oxml.ns import qn
class MySQLWordDocGenerator:
def __init__(self, host, user, password, database, port=3306):
self.host = host
self.user = user
self.password = password
self.database = database
self.port = port
self.connection = None
self.cursor = None
self.document = Document() # 初始化Word文档
def connect(self):
"""连接MySQL数据库"""
try:
self.connection = mysql.connector.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
port=self.port
)
if self.connection.is_connected():
self.cursor = self.connection.cursor(dictionary=True)
print(f"成功连接到数据库: {self.database}")
return True
except Error as e:
print(f"数据库连接失败: {e}")
return False
def get_all_tables(self):
"""获取所有表名"""
try:
self.cursor.execute("SHOW TABLES")
return [item[f'Tables_in_{self.database}'] for item in self.cursor.fetchall()]
except Error as e:
print(f"获取表列表失败: {e}")
return []
def get_table_comment(self, table_name):
"""获取表注释"""
try:
self.cursor.execute(f"SHOW TABLE STATUS LIKE '{table_name}'")
result = self.cursor.fetchone()
return result['Comment'] if result else "无"
except Error as e:
print(f"获取表 {table_name} 注释失败: {e}")
return "获取失败"
def get_table_structure(self, table_name):
"""获取表字段结构"""
try:
self.cursor.execute(f"DESCRIBE {table_name}")
return self.cursor.fetchall()
except Error as e:
print(f"获取表 {table_name} 结构失败: {e}")
return []
def get_table_indexes(self, table_name):
"""获取表索引信息"""
try:
self.cursor.execute(f"SHOW INDEX FROM {table_name}")
return self.cursor.fetchall()
except Error as e:
print(f"获取表 {table_name} 索引失败: {e}")
return []
def set_document_style(self):
"""设置文档样式(支持中文)"""
# 设置默认字体
style = self.document.styles['Normal']
font = style.font
font.name = '微软雅黑'
font.size = Pt(10)
# 解决中文显示问题
style._element.rPr.rFonts.set(qn('w:eastAsia'), '微软雅黑')
def add_title(self, text, level=1):
"""添加标题"""
para = self.document.add_paragraph()
run = para.add_run(text)
run.font.size = Pt(14 if level == 1 else 12)
run.font.bold = True
para.alignment = WD_ALIGN_PARAGRAPH.LEFT
def add_table_to_doc(self, data, headers, title):
"""添加表格到文档"""
self.document.add_paragraph(title, style='Heading 3')
if not data:
self.document.add_paragraph("无数据")
return
# 创建表格
table = self.document.add_table(rows=1, cols=len(headers), style='Table Grid')
# 设置表头
hdr_cells = table.rows[0].cells
for i, header in enumerate(headers):
hdr_cells[i].text = header
hdr_cells[i].paragraphs[0].runs[0].font.bold = True
# 填充数据
for row in data:
row_cells = table.add_row().cells
for i, key in enumerate(headers):
row_cells[i].text = str(row.get(key, ""))
self.document.add_paragraph() # 换行
def generate_word_doc(self, output_file):
"""生成Word文档"""
if not self.connection or not self.connection.is_connected():
print("请先连接数据库")
return
self.set_document_style()
# 文档标题
title = self.document.add_heading(f'MySQL数据库设计文档', 0)
title.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 基本信息
self.document.add_heading('基本信息', level=1)
info = [
f'数据库名称: {self.database}',
f'服务器地址: {self.host}:{self.port}',
f'生成时间: {datetime.now().strftime("%Y-%m-%d %H:%M:%S")}',
f'表数量: {len(self.get_all_tables())}'
]
for item in info:
self.document.add_paragraph(item)
self.document.add_page_break()
# 表结构详情
tables = self.get_all_tables()
for idx, table in enumerate(tables, 1):
self.document.add_heading(f'表 {idx}: {table}', level=1)
# 表注释
self.document.add_paragraph(f'表注释: {self.get_table_comment(table)}', style='Heading 2')
# 字段详情
structure = self.get_table_structure(table)
if structure:
# 转换字段数据为表格格式
field_data = []
for field in structure:
field_data.append({
'字段名': field['Field'],
'类型': field['Type'],
'允许为空': '是' if field['Null'] == 'YES' else '否',
'主键': '是' if field['Key'] == 'PRI' else '否',
'默认值': field['Default'] if field['Default'] is not None else '无',
'额外信息': field['Extra'],
'注释': field.get('Comment', '无') # 部分版本可能没有Comment字段
})
self.add_table_to_doc(
field_data,
headers=['字段名', '类型', '允许为空', '主键', '默认值', '额外信息', '注释'],
title='字段详情'
)
# 索引详情
indexes = self.get_table_indexes(table)
if indexes:
index_data = []
seen = set() # 去重
for idx_info in indexes:
idx_key = (idx_info['Key_name'], idx_info['Column_name'])
if idx_key not in seen:
seen.add(idx_key)
index_data.append({
'索引名': idx_info['Key_name'],
'字段名': idx_info['Column_name'],
'索引类型': idx_info['Index_type'],
'是否唯一': '是' if idx_info['Non_unique'] == 0 else '否',
'排序': 'ASC' if idx_info['Collation'] == 'A' else 'DESC' if idx_info[
'Collation'] == 'D' else '无'
})
self.add_table_to_doc(
index_data,
headers=['索引名', '字段名', '索引类型', '是否唯一', '排序'],
title='索引详情'
)
self.document.add_page_break() # 每个表分页
# 保存文档
try:
self.document.save(output_file)
print(f"文档已成功生成: {output_file}")
except Exception as e:
print(f"保存文档失败: {e}")
def close(self):
"""关闭数据库连接"""
if self.connection and self.connection.is_connected():
self.cursor.close()
self.connection.close()
print("数据库连接已关闭")
if __name__ == "__main__":
# 生成文档
generator = MySQLWordDocGenerator(
host="127.0.0.1",
user="root",
password="123456",
database="123456",
port=3306
)
output = "数据库设计文档v1.0.docx"
if generator.connect():
generator.generate_word_doc(output)
generator.close()运行后即可生成数据库设计文档,样式如图: